1915年插图–弗兰茨·卡夫卡的“变形”
在弗兰茨·卡夫卡的“变形记”中,一个人一天早上醒来,发现他已经变成了一只巨大的昆虫。如果关键字是存在主义者,他们可能会遇到类似的情况,已经被输入到Google的搜索栏,他们经历了大量的转换以成为新的,自己的修改版本 – 谷歌认为这是更好地表示搜索者的意图的查询。
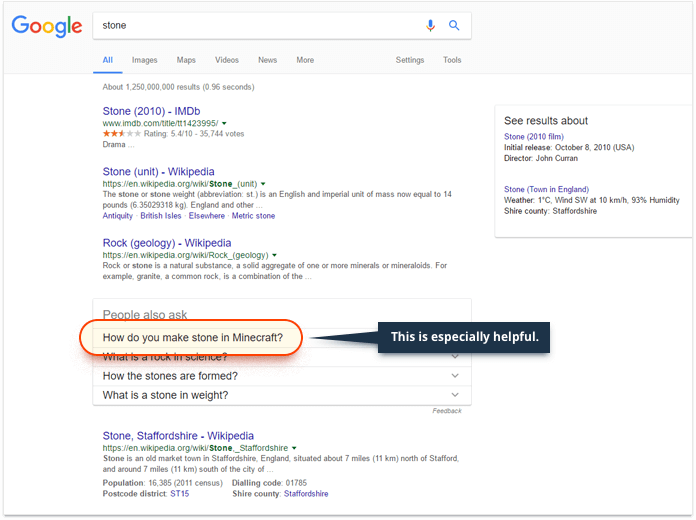
为了说明我在说什么,让我问你一个小小的好处。在Google上输入“oscar”。不,认真,做。我会挂在这里,而你在它。
机会是所有的顶部结果,你得到的是几天前发生的第89届奥斯卡颁奖典礼。一些结果可能没有提到单词“oscar”(你输入的唯一字,记住?)。不知为什么,Google知道你正在寻找具体的奥斯卡奖,而不是关于仪式,奥斯卡的名字,或奥斯卡的任何其他的一般信息,并将你的查询在幕后转换成几乎不相似于原来的东西。
在这篇文章中,我将看看这个过程如何工作,以及它对SEO的含义。
关联,相关性和搜索量
Google最近针对提供搜索查询优化的专利提供了许多关于Google如何处理模糊,过于笼统,过于狭窄或缺乏上下文(例如您刚刚完成的“奥斯卡”搜索)的搜索情况的洞察力。该专利描述了将查询转换为自己的更好语言版本的系统,以便Google可以准确地提供用户想要的搜索结果。
根据该专利,当Google收到查询时,将根据搜索者键入的关键字,从其与查询相关联的索引中抓取Web文档。然后,它将查看其提取的页面和概念,或语义聚类,它们是相关联的。如果它发现结果属于几个非常不同的概念,则很可能得出结论,该查询是不明确的并且将从精化中受益。
让我们试着看看实际的细化过程如何在“oscar”例子上工作。当您在Google中输入“oscar”时,它会继续并收集与该查询完全匹配的多个搜索结果。为了该示例的目的,假设该数字是100.向100个搜索结果中的每一个分配估计它们与原始查询(“oscar”)的相关性的分数,可能基于传统的页内和页外SEO因子。接下来,Google将去识别这些网页所属的主题或语义集群;对于“oscar”,这样的集群可以是:“奥斯卡奖”,“奥斯卡的名字”,“奥斯卡的鱼”,以及可能一些较小的。不知为什么,Google必须找出你感兴趣的这些概念 – 这是什么事情变得有趣。
根据该专利,Google将转而使用其“关联数据库” – 存储过去查询,网页以及两者之间的关联的位置。对于每个关联,Google会分配权重 – 网页与查询的相关程度,乘以查询的频率或搜索量。接下来,Google可能会查找刚刚为此数据库中的“oscar”查询提取的结果。它将查看与每个结果相关联的过去查询以及这些关联的权重。来自最高得分群集的最高得分关联将被挑选为精化查询的候选。
记住,权重是相关乘以搜索量,你可能开始明白为什么,在这个特定时刻,你搜索“奥斯卡”变成像“奥斯卡颁奖仪式2017”。
值得注意的是,Google通常会选择多个群集或主题来优化查询。当与原始关键字相关联的可能群集具有相等或接近相等的权重时,这是特别明显的,这时Google会让您决定您感兴趣的主题。
上下文
另一个专利阐明了上下文在改进用户查询方面的作用。在这种情况下,上下文是与单个域相关联的词和短语的集合。这样的“上下文”的数据从训练材料的大语料库获得,然后可能通过机器学习来改进和扩展。这些上下文可帮助Google更好地索引信息和提供搜索服务。对于前者,Google将“通信领域”划分为域,这与上面讨论的群集类似。通过查看网页及其中使用的字词和表达式,Google可以根据特定上下文中的字词与网页中的内容的交集,轻松找出网页可归属的上下文。因此,当它查看包含诸如“学院”,“奥斯卡奖”和“最佳电影”等词语的网页时,它会变成“哈哈,这页的上下文是奥斯卡颁奖典礼”。
在用户端,为了确定其查询的上下文,Google会查看用户的过去搜索记录,以及必要时查看其整个搜索记录。换句话说,如果您的搜索记录暗示您对奥斯卡鱼特别感兴趣,那么当您搜索奥斯卡时,Google可能会根据其作为搜索者的上下文信息,为鱼群相关群集提供帮助。所以事实上,你搜索“奥斯卡”变成“请搜索”奥斯卡“记住所有你知道我,谷歌”。
上下文2.0
您的搜索和浏览器历史记录不是Google可能用于优化查询的唯一一种“上下文”。几个最近的专利暗示,关于搜索者的更复杂的细节,例如他们看到的电影或他们收听的音乐可以用于改进查询并返回结果。当用户进行语音查询时,也可以使用实时上下文,例如当前正在播放的电影。
例如,用户可以在设备处输入自然语言查询,诸如口语查询“我什么时候看过这个演员?” 同时观看特定内容,例如电影“社交网络”。
根据这些专利,Google也可能会监控您所在地区的电视节目,并寻找可能与该信息相关的查询。因此,如果您搜索“社交网络”,并且电影“社交网络”目前在您所在的地区,则可能会影响您收到的搜索结果。例如,这可能优先于与您的查询相关联的其他语义集群的“社交网络电影”集群。
位置
位置,当然是一种上下文,但它应该在这个列表上自己的地方。位置已经影响了大量查询,对于企图让他们的网站在本地排名的企业尤其重要。但Google使用位置来优化查询可能很快就会超越当前状态。
您可能已经知道,如果您搜索“星巴克”,“沃尔玛”或某个实体,这可能意味着您对某个商家的实际位置感兴趣,Google会向您显示本地信息包,并调整自然搜索结果以帮助您找到您(可能)寻找的实际位置。这可以进一步,因为Google可以查看查询模式并将它们与接近搜索者位置的实体相关联。所以,如果你问谷歌“星巴克什么时候打开?”,甚至,“这个公园叫什么?”,而你所指的实体明确接近,谷歌将足够聪明,给你答案。

所以下一次你经过一家餐馆 – 让我们说这叫做Zio Pepe – 想知道它是否有什么好,尝试问谷歌“这个地方的任何评级? 这个查询可以变成类似“zio pepe评级”的东西,你不必担心“zio”如何在意大利语中发音。
例如,不会说德语的用户可以在瑞士苏黎世度假,并且可以在[营业时间]提交查询,同时站在名为“Zeughauskeller”的餐馆附近,这可能难以发音和/或拼写 用户。 作为另一示例,本公开的实施方式使得用户能够更方便和自然地与搜索系统交互(例如,提交查询[show me lunch specials]而不是查询[Fino Ristorante&Bar lunch specials])。
查询替换
由Google提交的另一个最近的专利集中于替换术语和同义词以用于查询细化。 该过程包括识别用户查询中的概念并且确定是否可以不同地表达相同的概念(不扭曲查询的含义)以提供更好的适合的搜索结果。
要了解这是如何工作的,让我们做一个谷歌搜索“英国总统”。 如果Google只是查询查询中提到的两个字,“英国”和“总统”,结果可能包括其他国家的总统访问英国的文章。 相反,Google认为搜索者可能寻找不同类型的信息,而“总统”一词实际上是当搜索者真正意味着“总理”时所犯的错误。 在给定的上下文中,“总理”是“总统”的同义词; 结合“英国”,它也代表一个已知的实体。 所有这一切使它成为一个好的替换术语。
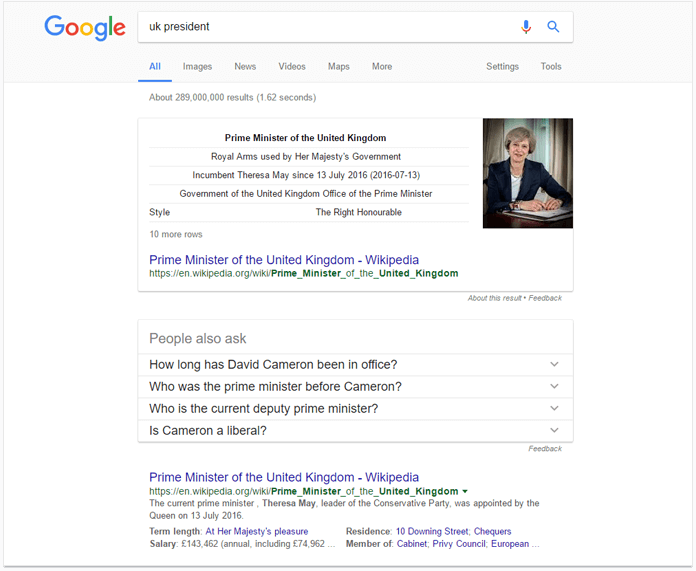
(请注意,Google如何在SERP的网址中加入“总理”,以及“总裁”一词在顶级结果中如何出现)。
Word2vec
关于word2vec在最近的SEO空间有很多讨论,最近由许多SEO表达的意见,它可能是谷歌的RankBrain使用的技术引发的。这个意见有其理由:许多在RankBrain工作的人也在word2vec工作,并且两个项目的许多描述几乎相同。
word2vec工具将文本语料作为输入,并生成单词向量作为输出。它首先从训练文本数据构造词汇表,然后学习单词的向量表示。所得到的单词矢量文件可以用作许多自然语言处理和机器学习应用中的特征。
在我们进入word2vec之前,让我们来解决一个问题。 SEO民众最近一直在谈论词向量和向量空间。虽然这些概念在理论上可能是复杂的,听起来像你需要采取微积分课程来掌握他们(如果你想要达到事物的底部,你可以做一些事情),但是他们个人的可视化实际上是令人惊讶的可以理解的。
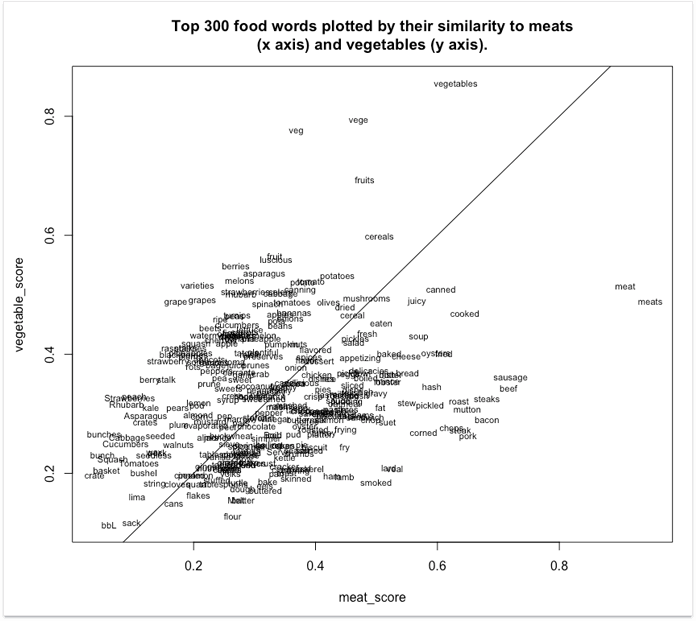
让我们来看一个简单的例子。假设你有一组术语,你需要分成两个集群,“蔬菜”和“肉”。不是所有的单词都是蔬菜或肉类,但是你必须这么做,将在肉类情境中出现的词语更频繁地分类(例如“熏制”)到“肉类”集群中,反之亦然。
这里是这些单词向量的可视化可能是什么样子。
来源: http://bookworm.benschmidt.org/
正如你所看到的,具有高“蔬菜”分数的术语朝向顶部,而具有高“肉”分数的术语朝右。接近中间的线是更中性的术语 – 在两种情况下同样频繁出现的术语。
重要的是要注意,将术语聚集到语义组中远不是word2vec可以做的唯一的事情。另一个重要方面是通过计算它们的向量之间的物理距离来识别术语之间的关系。上面,你可以看到“肉”和“肉”彼此相邻,因此在意义上是接近的。 “扒”,“牛排”和“猪肉”更紧密地捆在一起。注意,彼此相邻的词语不必是同义词。它们可以是经常彼此接近的术语,如“香蕉”和“苹果”。
现在,让我们向前迈进一步。我们已经知道,我们可以从彼此中减去向量来识别它们的相关性(距离越小,它们的相关性越强)。但是如果我们把两个向量加在一起呢?然后从总和中减去另一个向量?
显然,这正是Google对某些查询的做法。

对于上面的向量,方程式罗马 – 意大利+中国将等于北京。 事实上,这是一个问题“与罗马到意大利有中国关系的实体是什么?”,或者简单地说,“中国的首都是什么?
这里有一个例子,说明如何在查询处理中使用word2vec。 假设你暂时忘记了“toe”的词(你迫切需要这个词)。 感谢术语向量,你可以继续和谷歌的“手指”,然而奇怪的是,听起来,谷歌会得到你的意思。 它会发现手指是“手”概念的一部分,并将查询修改为类似“与手指到手有什么相同的关系”的东西。 (或者,在向量谈话中,“脚+手指”),并且将在该关联中寻找丢失的片段。 感谢你,你会看到你正在寻找什么(而不是提到“脚”和“手指”的页面列表)。

看看他们如何在特色答案中粗体显示“脚趾”,而没有提到单词“手指”? 聪明,是吗?
实体
实体是Google知识图的元素 – Google知道某些事实的具体对象,例如人物,地点和事物。 企业,名人或工厂可以是实体。 关于实体的伟大之处在于Google非常了解它们,这让搜索者可以通过某种事实立即找到一个实体。
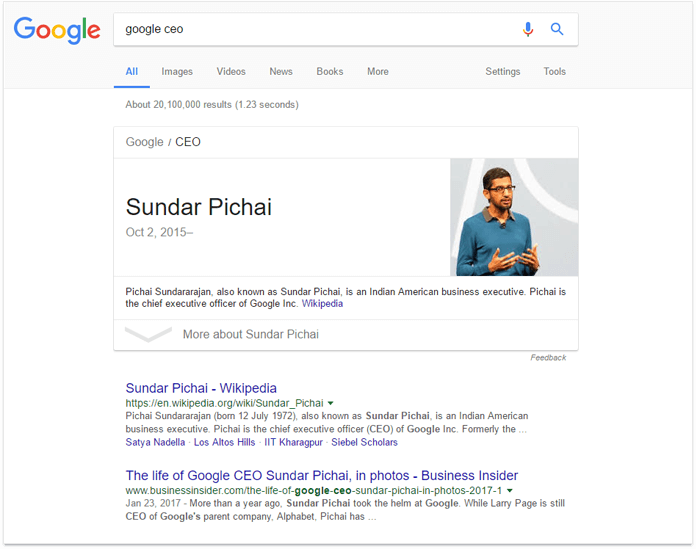
因此,搜索Google认为是某个实体的唯一属性的内容会产生该实体的搜索结果。 这样,“世界上最大的城市”可以转化为“哪个实体具有成为世界上最大的城市的独特属性? 并匹配东京的实体。 同样,“Google CEO”将与Sundar Pichai合作。
种类,你想要有一个独特的,客观的特点为您的企业的实体,不是吗?
有趣的是,用户行为信号可能像任何其他类型的结果一样影响这种基于实体的搜索结果。说,如果Google发现两个具有相似权重的实体与查询匹配,则通常会在SERP中显示相关的结果。如果您搜索“Joe’s NYC”,只要您以前从未进行过搜索,您就会看到一些商家的名称:Joe的酒吧,Joe的酒吧,Joe的咖啡店和Joe的披萨店。但是,一旦您点击某个结果(例如,比萨饼店),Google可能会在此搜索的上下文中将此实体存储为您的首选实体。因此,当您再次运行类似的搜索时,您的首选实体将可能显示在结果的顶部,而其他实体可能会从SERP中完全删除。
最后的话
以上表明,谷歌正在迅速变得更聪明(即使你愿意),在找出关键字的意义,改写这些关键字,并产生更好的搜索结果作为回应。我们可能会看到这是坏消息或好消息,但我们没有什么能做,只有适应。
我想让你从这篇文章中摘取的一个概念是,用户看到的搜索结果不仅仅是查询和排名因素的组合。在中间,Google可以修改查询,以便它可以更好地回答它,并且这种修改过程对于各种查询可能非常不同 – 甚至对于在不同时间点进行的相同查询(假设搜索“oscar”几个几个月后)。
所以有什么SEO现在仍然可以做,我们纠结在这个语义网络?当然。这里有一些提示。
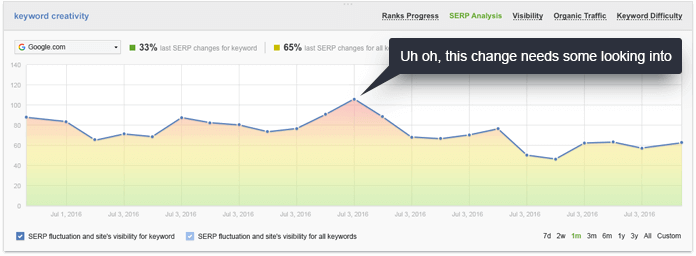
1)获取知识图。虽然没有神奇的公式,肯定会让你,有一些步骤,将大大提高你的机会,赢得你的业务知识图表上市。以下是本地知识图表面板的步骤,以及更通用的品牌知识图表的步骤。
2)继续争取这些排名。我一直对一些SEO开始怀疑排名作为SEO KPI的价值感到惊讶,因为搜索的个性化越来越多。不要忘记,当有人首次对您的目标关键字进行搜索时,您必须尽量在顶部结果中显示。如果您这样做,如果搜索者点击您的商家信息,您将成为他们的首选实体,随后的搜索可能会将您的商家作为结果中的顶部(如果不是唯一)实体。否则,如果您的竞争对手位于顶部,而搜索者点击了他们的商家信息,您可能失去了该客户。
3)密切监控您的利基。现在很清楚,Google可能会对不同的市场甚至个别查询使用不同的排名因素(以及不同的查询细分)。 SEO的普遍方法,其链接和网站结构的基础仍然有效;但在某个查询的上下文中,它可能超过了该查询或利基特定的其他因素。例如,在SEO PowerSuite的排名跟踪器中,我们将其称为SERP历史记录 – 针对您运行的每个排名检查的前30个搜索结果的归档(为了保存SERP历史记录,您需要一个排名跟踪器许可证键)。如果您查看SERP波动图,您可以在每个关键字排名检查期间立即发现SERP中的重要更改。图形上的红色尖峰将立即让你知道,在SERP中有一个重要的变化,你需要看看。这可能表示Google开始以不同的方式解释查询,或者开始查看不同的排名因素。在任何一种情况下,最好与SERP核对,看看发生了什么变化,这样你就可以第一次适应。